In early 2024 I started a project called Cloud Insight Index which went through AWS, GCP, and Azure public incident postings and collects information about each incident in 2023.
This post is the 2024 edition. See the project’s page for methodology and 2023’s numbers. Unfortunately, AWS/GCP’s incident postings do not go back to January 2023 and I don’t have last year’s dataset so I can’t do a year-over-year comparison across providers. I’ll make sure to keep a copy of this year’s data to be able to do a comparison next year.
Disclaimer: The data being analyzed is imperfect, but I think it can reasonably approximate a cloud provider’s (and the industry’s) overall “vibe” toward communicating incidents, service availability, resolution times, and blast radius tendencies.
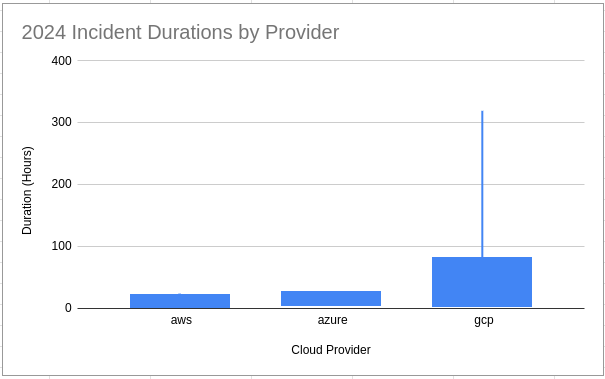
Duration Summary Stats grouped by provider
| provider | event_count | avg_duration_hours | median_duration_hours | p95_duration_hours | p99_duration_hours | p100_duration_hours |
|---|---|---|---|---|---|---|
| aws | 27 | 3.54 | 1.88 | 21.83 | 24.00 | 24.00 |
| azure | 13 | 10.99 | 5.27 | 26.25 | 26.25 | 26.25 |
| gcp | 156 | 14.56 | 3.86 | 82.07 | 155.08 | 319.37 |
Which provider/region had the most incidents?
| provider | region | distinct_event_count |
|---|---|---|
| aws | global | 10 |
| azure | us-east-3 | 13 |
| gcp | us-central1 | 64 |
NOTE: AWS considers some services like Route53 and IAM as “global”.
Which provider/service had the most incidents?
| provider | service | distinct_event_count |
|---|---|---|
| aws | ec2 | 9 |
| azure | azure-applied-ai-services | 13 |
| gcp | Chronicle Security | 28 |
What was the longest incident per provider?
| provider | event_id | duration_hours |
|---|---|---|
| aws | arn:aws:health:us-east-1::event/MULTIPLE_SERVICES/AWS_MULTIPLE_SERVICES_OPERATIONAL_ISSUE/AWS_MULTIPLE_SERVICES_OPERATIONAL_ISSUE_F0449_625BDDE4846 |
23.9997222237289 |
| azure | VT60-RPZ |
24.4500000067055 |
| gcp | 2GcJSJ2mZp3xw91PbJ87 |
319.366666663438 |
AWS Notes
For the hosts hosting the unusually large number of shards, the status messages became very large in size. With this increase in message size, these messages were unable to be transmitted to, and processed by, the cell management system in a timely fashion and the processing of status messages from some other hosts became delayed. When the cell management system did not receive status messages in a timely fashion, the cell management system incorrectly determined that the healthy hosts were unhealthy and began redistributing shards that those hosts had been processing to other hosts. This created a spike in the rate of shard redistribution across the impacted Kinesis cell and eventually overloaded another component that is used to provision secure connections for communication to Kinesis data plane subsystems, which in turn impaired Kinesis traffic processing.
The incident happened while migrating to a hardened architecture. There are difficulties in production, especially the rumored largest production region in the world (us-east-1), that can be difficult to anticipate.
Cascading failures.
Azure Notes
The incident resulted from multiple concurrent fiber cable cuts that occurred on the west coast of Africa (specifically the WACS, MainOne, SAT3, and ACE cables) in addition to earlier ongoing cable cuts on the east coast of Africa (including the EIG, and Seacom cables). These cables are part of the submarine cable system that connect Africa’s internet to the rest of the world, and service Microsoft’s cloud network for our Azure regions in South Africa. In addition to the cable cuts, we later experienced impact reducing our backup capacity path, leading to congestion that impacted services.
Physical site problems like fiber cuts take a long time to mitigate, diagnose, and fully recover. Systems can surprise us with degraded states, and backup/degraded capacity has to be a part of ongoing capacity planning processes.
Network infrastructure between South Africa West and South Africa North are (were?) shared.
GCP Notes
Deployment of large models (those that require more than 100GB of disk size) in Vertex AI Online Prediction (Vertex Model Garden Deployments) failed in most of the regions for a duration of up to 13 days, 6 hours, 22 minutes starting on Tuesday, 22 October 2024 at 14:08 US/Pacific.
From preliminary analysis, the root cause of the issue is an internal storage provisioning configuration error that was implemented as part of a recent change.
Google engineers mitigated the impact by rolling back the configuration change that caused the issue.
Google did not publish any more of a thorough incident report. Perhaps this should not have been an Incident because it only impacted customers requiring 100GB in disk size.
Vertex AI appears to share some components globally, as there were service impacts in Asia, Austrailia, America, and Europe.
What incident had the largest blast radius?
Thishttps://rachelbythebay.com/w/2020/10/26/num/ is measured by the distinct number of region-services combinations that were mentioned in a given Incident. For instance, if EC2 were impacted across 5 regions during a single Incident, that would count as 5 services impacted.
| provider | event_id | num impacted |
|---|---|---|
| gcp | xVSEV3kVaJBmS7SZbnre |
1312 |
| azure | 0N_5-PQ0 |
307 |
| aws | arn:aws:health:us-east-1::event/MULTIPLE_SERVICES/AWS_MULTIPLE_SERVICES_OPERATIONAL_ISSUE/AWS_MULTIPLE_SERVICES_OPERATIONAL_ISSUE_F0449_625BDDE4846 |
65 |
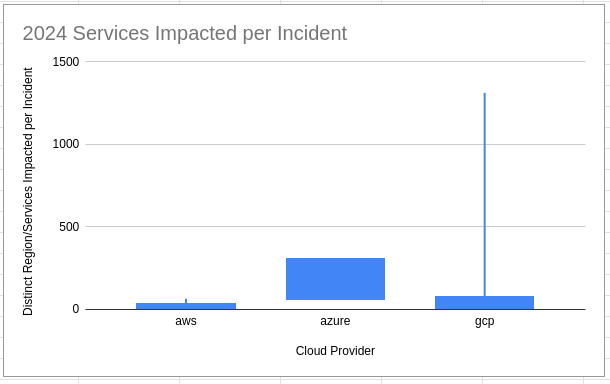
Blast Radius Summary Statistics
| provider | avg_event_count | median_event_count | p95_event_count | p99_event_count | p100_event_count |
|---|---|---|---|---|---|
| aws | 10.11 | 1.00 | 35 | 65 | 65 |
| azure | 86.54 | 61.50 | 307 | 307 | 307 |
| gcp | 26.25 | 4.00 | 78 | 246 | 1312 |
AWS Notes
This is the same incident as the earlier “AWS Notes” writeup.
Azure Notes
While the rollout of the erroneous configuration file did adhere to our Safe Deployment Practices (SDP), this process requires proper validating checks from the service to which the change is being applied (in this case, AFD) before proceeding to additional regions. In this situation, there were no observable failures, so the configuration change was able to proceed – but this represents a gap in how AFD validates the change, and this prevented timely auto-rollback of the offending configuration – thus expanding the blast radius of impact to more regions.
Even with sophisticated practices and systems with guard rails around risk, systems have to surface all types of failures. It’s often better to invest in detection over remediation.
The error in the configuration file caused resource exhaustion on AFD’s frontend servers that resulted in an initial moderate impact to AFD’s availability and performance. This initial impact on availability triggered a latent bug in the internal service’s client application, which caused an aggressive request storm. This resulted in a 25X increase in traffic volume of expensive requests that significantly impacted AFD’s availability and performance.
Exponential backoff clients and services with Load Shedding should be the default.
GCP Notes
The root cause was a bug in maintenance automation intended to shut down an unused VPC Controller in a single zone. A parameter specifying the zone for maintenance operations was modified during a refactor of the automation software earlier in the year. This modification resulted in the target zone parameter being ignored and the shut down operation taking effect on VPC controllers in all cloud zones. The test environment caught this failure mode, but the error was misinterpreted as an expected failure in the test environment. As a result, the change made it to production.
Ouch and ouch. “Expected failure in the test environment” was triggering.
Shutdowns are a routine operational practice that we perform to maintain our systems without customer impact. The automation has a safeguard in place to limit the scope of maintenance operations. This safeguard was inadvertently disabled during a migration to a new version of the automation framework, resulting in the shutdown operation taking effect on VPC controllers in all cloud zones.
Accidentally operating on too many systems is a common enough problem, I’m surprised Google hasn’t solved this.
Overall Takeaways
- Unsurprisingly AWS has the fastest incident resolution times and incidents with lowest blast radius. I’m no AWS fanboy but there’s no compression algorithm for experience.
- Azure’s transparency and incident reviews are by far the most thorough.
- Providers are leaning in to dependencies across services and regions, which increases difficulties for customers to mitigate outages. Employing multi-region strategies for a single provider is less likely to help.
- Running services is the hard part of being a cloud provider. The Incidents I reviewed were all a part of evolving systems, either by turning old resources off, changing an architecture in place, or fiber optic cable cuts that Just Happen.