We had some storage issues. We still have some storage issues, but it’s getting better. Here’s what we’ve fixed:
-
Overbooked storage
-
Storage Switch Failure Tolerance
-
Adapter Failure Tolerance
Overbooked Storage Units
The most immediate issue that could be addressed was the storage bloat. This did not require additional hardware. Previously, our storage allocated for VMware was as follows:
-
VMFSLun1 (600 GB)
-
VMFSLun2 (900 GB)
All 30 virtual machines the university ran (46 individual virtual hard disks) were running on two LUNs. Through collaboration with the SAN administrator, VMware’s Storage vMotion technology, and the SVMotion Plugin[ 3], the LUNs were balanced as much as possible without the addition of new hardware. The new storage is laid out as follows, per NetApp & VMware recommendations [ 1] [ 2]:
-
VMFSLun1 (300 GB – reallocated from old VMFSLun1)
-
VMFSLun2 (300 GB – reallocated from old VMFSLun1)
-
VMFSLun3 (300 GB – reallocated from old VMFSLun2)
-
VMFSLun4 (300 GB – reallocated from old VMFSLun2)
-
VMFSLun5 (300 GB – reallocated from old VMFSLun2)
-
Templates_and_ISOs (50 GB - new)
-
VMFSLun6 (300 GB - new)
We reorganized their existing allocated storage (1500 GB) into a more optimized layout. Additionally, a 50 GB LUN was added (Templates_and_ISOs) for organizational purposes. The need for additional storage capacity was identified and VMFSLun6 was created with existing iSCSI storage.
Switch and Adapter Fault Tolerance
During the procurement process, Information Systems staff planned to implement the new hardware. We then created a plan.
The existing storage setup had 3 hosts, 30 virtual machines (46 virtual disks) attached to two LUNs with one host based adapter (HBA) and one path. The filers are redundant in the sense that they are clustered for IP takeover, but there were two additional points of failure:
-
If a host’s HBA failed, the VMs would be unavailable and data would be lost.
-
If the switch the any of the cluster’s HBAs are connected to failed, all virtual machine disks would be unavailable and all virtual machines would likely incur data loss.

Figure 1.1 – Before the upgrade, HBA fault tolerance diagram
The new storage adapter fault tolerance plan had two major goals: tolerance of a switch failure and tolerance of a storage adapter failure. Planning to tolerate switch failure was straightforward: attach the additional HBA into another switch. Planning to tolerate HBA failure for a given LUN was handled with VMware’s Virtual Infrastructure Client.
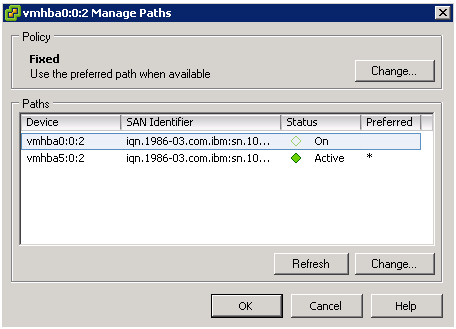
Managing Paths within VI Client.
After we received the new HBAs, each host was brought down with no downtime. The new HBAs were placed in the hosts, and connected to the additional switches. The hosts were brought back up and primary paths were set in the VI Client per LUN.
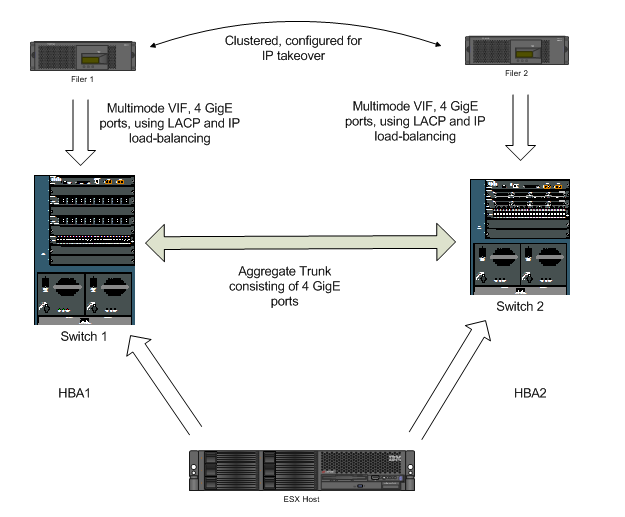
Diagram of our Virtual Infrastructure showing HBA and switch fault tolerance
Storage Performance
Multiple paths to LUNs serves as an important point which will also help us lessen LUN contention and increase IO performance. Now that there are two available paths for each LUN, the “hot” paths can be evenly split between HBAs, increasing the total throughput per HBA. Previously, we had all LUN traffic travel through a single point (HBA 1), and each virtual disk per LUN had to be accommodated.
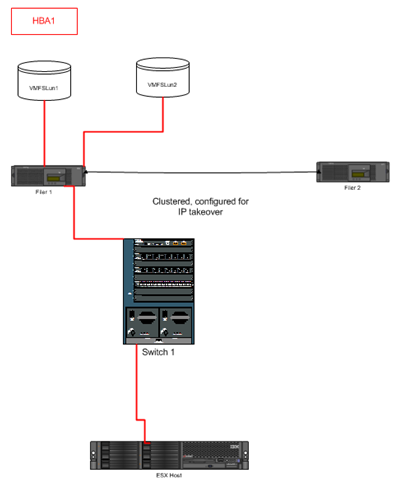
Our previous LUN / path layout
With the additional path along with the better balanced LUNs (see “Overbooked Storage”) the new structure has six LUNs, but only 3 being used by each HBA. This layout means less total traffic through each HBA per LUN.
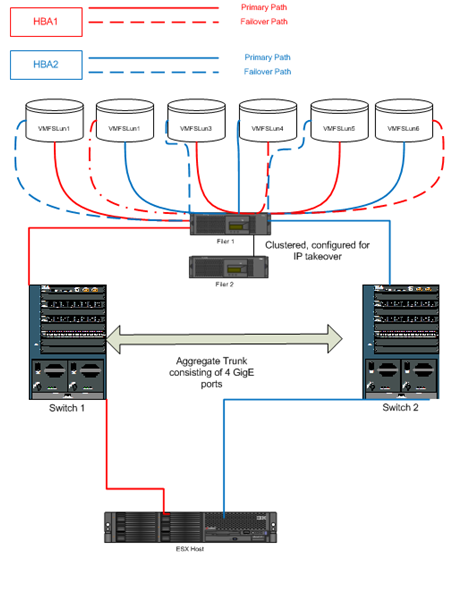
Our Current Storage Layout, demonstrating multiple paths and lower LUN contention
[1] “SAN System Design and Deployment Guide”, VMware
http://www.vmware.com/resources/techresources/772
[2] “NetApp and VMware Virtual Infrastructure 3 Storage Best Practices”, NetApp; page 11
http://media.netapp.com/documents/tr-3428.pdf
[3] “VI Plug-in – SVMotion”, Schley Andrew Kutz
http://sourceforge.net/project/showfiles.php?group_id=228535